
Hace (tan solo) siete años terminaba un artículo para La Linterna del Traductor sobre la historia de la traducción automática. En él ya avanzaba cómo la traducción automática era un gran tema de investigación en el mundo académico y los traductores debíamos estar al tanto de sus últimos avances para que los posibles cambios que se avecinaban en el sector no nos pillasen desprevenidos. También mencionaba cómo, en esos momentos, varios grupos de investigación estaban explorando diversas estrategias, desde aquellas basadas en la interlingua (recordemos el proyecto Molto de la UE) hasta los sistemas basados en reglas de transferencia como Apertium, pasando por sistemas puramente estadísticos como Moses.
En este tiempo la traducción automática ha irrumpido de pleno en la traducción profesional. A estas alturas, nadie pone en duda que está aquí para quedarse, pero… ¿cómo hemos llegado hasta aquí?
En este artículo nos acercamos al presente para ver cómo la traducción automática ha evolucionado en estos siete años y cuáles son las técnicas más empleadas actualmente. ¿Te interesa? Acompáñame entonces en este breve recorrido por la historia más reciente de la traducción automática. ¡Empezamos!
En su investigación trata de establecer lazos de unión entre traductores y traducción automática. Entre sus artículos más recientes destacan los enfocados a evaluar la calidad de la traducción automática y el impacto de la traducción automática en la productividad de los traductores profesionales. Actualmente trabaja en el equipo de Sharon O’Brien en DCU investigando la posibilidad de introducir la traducción automática como una herramienta de ayuda para la redacción de artículos científicos en inglés por parte de no nativos. También colabora en un proyecto sobre traducción en situaciones de crisis humanitarias.
Actualmente podría decirse que conviven principalmente tres tipos de traducción automática (TA) en el mercado: la que utiliza información lingüística (comúnmente denominada como TA basada en reglas, o RBMT por sus siglas en inglés: Rule Based Machine Translation), la estadística (o SMT por sus siglas en inglés: Statistical Machine Translation) y la basada en redes neuronales (o NMT por sus siglas en inglés: Neural Machine Translation). A estos tres paradigmas principales habría que sumar otras iniciativas con menor proyección, como la propuesta por investigadores de la universidad de Gotemburgo (Suecia) basada en el concepto de interlingua y llamada Grammatical Framework1.
Puesto que la investigación en los distintos paradigmas de traducción automática se ha llevado a cabo en paralelo, en lugar de hacer una descripción de su evolución en orden cronológico vamos a ver cómo ha evolucionado cada uno.
Traducción automática basada en reglas
Comenzamos con este paradigma que, si bien sigue teniendo cabida en la investigación, es quizás el que menos atención acapara, aunque no por ello se deba obviar. Una de las posibles razones por las que este tipo de traducción automática no tiene más presencia en la investigación es porque requiere de una gran inversión en tiempo y recursos. Para desarrollar un único par de lenguas es necesario contar con gramáticas de la lengua de partida y de llegada, así como con diccionarios bilingües y reglas de transferencia. Además, el sistema no puede traducir estructuras lingüísticas que no estén incluidas en sus gramáticas o reglas de transferencia, ni palabras o expresiones que no se encuentren en sus diccionarios. Esto hace que el mantenimiento de los motores basados en reglas deba ser prácticamente continuo para garantizar que son capaces de traducir textos de un nuevo dominio, por ejemplo, o estructuras gramaticales que en un primer momento no fueron previstas.
[El paradigma de la traducción automática basada en reglas,] si bien sigue teniendo cabida en la investigación, es quizás el que menos atención acapara.
Otra posible razón es que ya contamos desde hace varios años con una plataforma de código abierto que permite a cualquier persona desarrollar su propio motor de traducción: Apertium. Con una comunidad de desarrolladores repartidos por todo el mundo, Apertium surgió en nuestro país, del grupo de investigación Transducens, en la Universidad de Alicante.
Si bien, como hemos visto, estos sistemas tienen inconvenientes, también presentan grandes ventajas. Para empezar, en el caso de lenguas similares entre sí, como por ejemplo el español y el catalán, se ha demostrado que obtienen resultados mejores que los motores estadísticos. Un buen ejemplo de esto último es que Apertium es uno de los sistemas de traducción automática que se utilizan en la plataforma de traducción automática (PLATA) desarrollada por la Dirección de Tecnologías de la Información y las Comunicaciones del Gobierno de España y disponible para cualquier Administración Pública del Estado. En concreto, Apertium se utiliza para facilitar la traducción automática de catalán, gallego, valenciano, portugués y francés, mientras que para el euskera y el inglés se utiliza un sistema estadístico.
Apertium se utiliza para facilitar la traducción automática de catalán, gallego, valenciano, portugués y francés, mientras que para el euskera y el inglés se utiliza un sistema estadístico.
Y, si bien es cierto que la traducción automática basada en reglas no es la predominante en el mundo académico, hay que reconocer que su utilidad puede ir mucho más allá de lo que nos imaginamos. Debido a que los sistemas estadísticos y neuronales necesitan una gran cantidad de datos para ser entrenados, la traducción automática basada en reglas puede resultar particularmente útil en el caso de pares de lenguas para los que no se cuenta con datos suficientes como para entrenar otro tipo de motores. Es por eso que Apertium se ha convertido en un gran catalizador para el desarrollo de motores con lenguas minoritarias. Otra muestra de su gran utilidad la podemos encontrar en proyectos de la organización Translators without borders, que ha desarrollado diversos pares con lenguas minoritarias para poder facilitar servicios de traducción. Por ejemplo, a finales de 2016 anunciaron el lanzamiento de sistemas para lenguas kurdas con el objetivo de dar asistencia a refugiados kurdos.
Traducción automática estadística

Como alternativa a los costosos procesos de desarrollo de un traductor automático basado en reglas, se pueden emplear los llamados traductores automáticos estadísticos. Su principal ventaja frente a los basados en reglas es que «tan solo» necesitan datos para ser entrenados. En concreto, necesitan un corpus monolingüe de la lengua de destino lo más grande posible y otro paralelo con traducciones entre la lengua de origen y la de destino.
Estos sistemas de traducción automática constan de tres componentes principales: el modelo de lenguaje, el modelo de traducción y el decodificador. El modelo de lenguaje se encarga de calcular la probabilidad de que una frase en la lengua de destino sea correcta. Es el encargado de la fluidez de la traducción y para entrenarlo se utiliza un corpus monolingüe de la lengua de destino lo más grande posible. Por su parte, el modelo de traducción se encarga de establecer la correspondencia entre el idioma de origen y el idioma de destino y se entrena utilizando un corpus alineado a nivel oracional. Durante esa fase de entrenamiento, el sistema estima la probabilidad de una traducción a partir de las traducciones que aparecen en el corpus de entrenamiento. Por último, el decodificador es el responsable de buscar dentro de todas las traducciones posibles la más probable en cada caso. Así, dado un modelo de lenguaje y un modelo de traducción, crea todas las traducciones posibles y propone la más probable.
Gracias a los avances en la investigación, estos sistemas, que en un principio producían traducciones muy pobres, llegaron a alcanzar resultados aceptables e irrumpieron en la vida de los traductores profesionales hace pocos años. Entre estos avances se incluyen mejoras en todos los componentes de un motor de traducción automática estadístico, desde la forma de realizar alineaciones suboracionales para mejorar el modelo de traducción, hasta la incorporación de información lingüística como parte del entrenamiento o la incorporación de otras técnicas de procesamiento del lenguaje natural y del aprendizaje automático. Obviamente, la calidad de dichos motores depende de diversos factores, como el par de lenguas empleado, la calidad de los corpus de entrenamiento, el campo, etc. Sin duda, el gran referente de estos sistemas es Moses, un sistema de traducción automática estadística de código libre desarrollado gracias a diversos proyectos de investigación europeos que cuenta con colaboradores de todo el mundo.
Estos sistemas, que en un principio producían traducciones muy pobres, llegaron a alcanzar resultados aceptables e irrumpieron en la vida de los traductores profesionales hace pocos años.
Con los primeros intentos de utilizar TA en entornos profesionales llegaron también iniciativas que pretendían acercar la traducción automática estadística a los traductores o usuarios fuera del mundo académico o de los círculos de desarrollo de motores de TA. De esta manera nacieron proyectos como Moses for mere mortals, que pretendía acercar la traducción estadística a cualquier persona que estuviera interesada en ella, y Moses for localisation (m4loc), que buscaba adaptar la traducción automática estadística para el sector de la localización. En los últimos años han surgido también soluciones comerciales como Slate que pretenden facilitar a los traductores el acceso a estas tecnologías y permitirles entrenar sus propios motores de traducción automática en su ordenador. Otras propuestas, aunque basadas en la nube, son las de KantanMT, unaempresa emergente irlandesa, o Lilt, una estadounidense. Lilt tiene además la particularidad de ofrecer una función llamada «traducción automática interactiva», que permite al usuario seleccionar la palabra siguiente de la traducción y, en función de la palabra seleccionada, cambia la propuesta de traducción. Y si nos fijamos en los resultados de proyectos de investigación europeos hay que señalar sin duda alguna MateCAT, una herramienta de traducción asistida en la nube que incorpora traducción automática. Liderada por la Fundación Bruno Kessler de Trento (Italia) y en colaboración con la empresa italiana de traducción Translated Srl., la universidad de Le Mans (Francia) y la universidad de Edimburgo (Reino Unido), esta herramienta se ha convertido en una alternativa para la traducción profesional. Además de disponer de la versión en línea para cualquier usuario mantenida por Translated, también es posible descargarse el código e instalarla en un servidor local con nuestros propios motores de traducción.
Traducción automática basada en redes neuronales
La última aparición en la familia de los paradigmas de traducción automática es la de los motores basados en redes neuronales en 2014 (Bahdanau, Cho y Bengio 2014, Cho et al. 2014). Se suele considerar como precursor de este paradigma un artículo publicado por dos investigadores españoles, Mikel Forcada y Ramón Ñeco, en el año 1997, en el que ya entonces proponían el uso de redes neuronales para la traducción automática. Si aquella idea no se llevó a la práctica fue, en parte, por una limitación muy clara: para poder llevar a cabo experimentos se necesitaban ordenadores y procesadores muy potentes, algo que en esos años no estaba al alcance de cualquiera. Actualmente, sin embargo, son muchos los centros de investigación que ya cuentan con acceso a supercomputadores donde entrenar este tipo de motores de traducción automática. Y esto mismo ha fomentado su investigación, así como los grandes avances que se han conseguido, principalmente en los dos últimos años. En 2016 fueron precisamente estos motores los grandes ganadores en las competiciones que se organizan anualmente en el ámbito académico.
Al igual que los sistemas estadísticos de traducción automática, los sistemas basados en redes neuronales necesitan grandes corpus paralelos para su entrenamiento. De hecho, para que funcionen correctamente suelen necesitar que esos corpus paralelos sean aún más grandes que los que se necesitaban en el caso de la traducción automática estadística. Estamos hablando no ya de millones de palabras, sino de millones de oraciones. La diferencia consiste en el método computacional que se utiliza para realizar las traducciones: las redes neuronales artificiales.
Los sistemas basados en redes neuronales necesitan grandes corpus paralelos para su entrenamiento.
¿Cómo funciona este sistema? No podemos entrar en grandes detalles, ya que necesitaríamos una gran base de álgebra, pero vamos a intentar quedarnos con una idea simplificada2: estas redes pretenden emular la manera en la que funcionan las neuronas en nuestro cerebro. Del mismo modo en que nuestras neuronas reciben información y realizan conexiones entre sí, los componentes del lenguaje se asocian con otra información subyacente para formar asociaciones y generar traducciones. Así, utilizando técnicas de aprendizaje automático, el ordenador aprende a traducir a partir de grandes cantidades de textos paralelos que además incluyen todo tipo de información lingüística y no lingüística.
Cada palabra se convierte en sí misma más toda su información asociada, y esa información se utiliza para entrenar el motor. Gracias a la manera de relacionar la información asociada a cada palabra y a la de las palabras de una frase, el ordenador es capaz de aprender a traducir de una manera más eficiente.
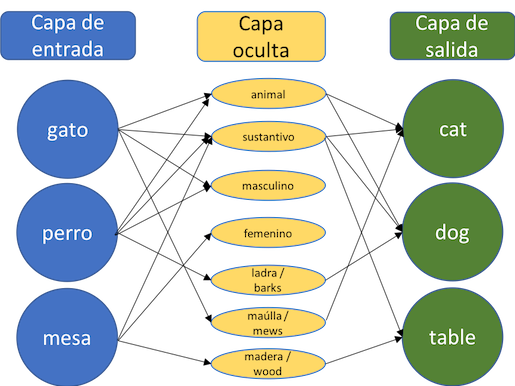
De este modo, utilizando redes neuronales artificiales el sistema puede aprender, por ejemplo, que los términos «perro» y «gato» son más similares entre sí que «perro» y «mesa», ya que en el texto generalmente estarán rodeados de palabras similares que nos pueden dar pistas sobre traducciones posibles.
En 2016, investigadores de la Universidad de Edimburgo desarrollaron un motor basado en redes neuronales que utilizaba caracteres y secuencias de estos en lugar de palabras completas como unidades lingüísticas (Sennrich, Haddow y Birch 2016). Al utilizar esta estrategia resultó que el sistema no solo era capaz de aprender palabras y sus traducciones, sino también declinaciones, conjugaciones de verbos, concordancias, etc. Los resultados obtenidos fueron tan prometedores que actualmente la mayoría de los sistemas basados en redes neuronales utilizan secuencias de caracteres en lugar de palabras en su entrenamiento. Pese a sus obvias ventajas, este enfoque también tiene desventajas, ya que en ocasiones los traductores automáticos generan palabras que consideran «probables» en la lengua meta, pero que sin embargo no existen o carecen de sentido alguno.
El potencial de la traducción automática basada en redes neuronales es tal que ya se están entrenando motores que, además de textos, incorporan imágenes o incluso archivos multimedia con resultados muy prometedores (por ejemplo, Calixto et al. 2017).
¿Neuronal o estadístico?
Los sistemas basados en redes neuronales han llegado a superar a los sistemas estadísticos hasta tal punto que los desarrolladores del sistema estadístico más utilizado hasta la fecha (Moses) anunciaron en octubre de 2017, al lanzar la versión 4 del sistema, que esta sería la última versión completamente probada en plataformas. Semejante anuncio parece indicar que los investigadores están convencidos de que este paradigma que había liderado la traducción automática desaparecerá para dejar paso a sistemas más complejos computacionalmente.
La revolución causada por los sistemas basados en redes neuronales recuerda a la que causaron los primeros prototipos de motores de traducción en los años 50.
Si pensamos en la historia de la traducción automática, la revolución causada por los sistemas basados en redes neuronales recuerda a la que causaron los primeros prototipos de motores de traducción en los años 50. Es por eso que muchos investigadores también han tratado de desmitificar que la traducción automática sea ya un problema resuelto como algunos se han atrevido a sugerir (Wu et al. 2016); durante el último año y medio se han publicado una serie de estudios que comparan los resultados de los motores estadísticos y los basados en redes neuronales con el fin de determinar si realmente las traducciones son tan superiores como indican las métricas de evaluación automática, y qué tipo de errores podemos encontrarnos (Bentivogli et al. 2016, Burschardt et al. 2017, Castilho et al. 2017a, 2017b, Popović 2017, Toral y Sánchez-Cartagena 2017). Todos los estudios indican que poseditar motores basados en redes neuronales puede ser más complejo de lo que podría parecer en un principio, porque estos sistemas suelen generar traducciones que en un primer momento parecen más correctas pero que en realidad no siempre lo son. Esto se debe a que generalmente las frases son gramaticales y tienen sentido, por lo que un cambio de significado puede pasar desapercibido si la frase en sí es posible dentro del contexto en el que se encuentra.
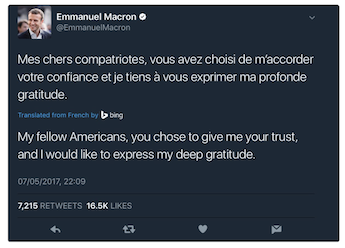
Puede, por ejemplo, que el sistema cambie en la traducción el nombre de un país por el de otro simplemente porque ha aprendido que, en contextos similares, en la posición N de la oración suele aparecer el nombre de ese país. También se ha demostrado que en el caso de frases muy largas (de más de 25-30 palabras) los sistemas basados en redes neuronales suelen obtener peores resultados que los sistemas estadísticos.
¿Quieres hacer tu propia comparación? Microsoft Translator ofrece esta opción.
Las pequeñas y medianas empresas aún se encuentran con barreras para poder implantar estos sistemas y en muchos casos siguen utilizando motores estadísticos.
Por último, cabe destacar que, si bien en el ámbito académico parece que los sistemas basados en redes neuronales están a la orden del día, en el sector de la traducción todavía se están incorporando poco a poco. Mientras las grandes corporaciones como Google, Microsoft, eBay o Booking.com pueden permitirse invertir en supercomputadores para entrenar sus motores de traducción automática, las pequeñas y medianas empresas aún se encuentran con barreras para poder implantar estos sistemas y en muchos casos siguen utilizando motores estadísticos. KantanMT ofrece a sus clientes la posibilidad de entrenar motores neuronales y la tecnología está avanzando a pasos agigantados, pero para poder llegar a competir con sistemas como Google Translate, Microsoft Translator o el recién incorporado a escena DeepL, además de acceso a supercomputadores se precisa acceder a grandes bases de datos por lo que, más que probablemente, de momento estos sistemas seguirán fuera del alcance de los traductores autónomos y las empresas de un tamaño modesto. ¿Por cuánto tiempo? Eso sí que es más difícil de predecir. Ya existen algunas propuestas de traducción automática neuronal que pretenden disminuir la cantidad de datos necesaria para entrenar motores. Es la llamada zero-shot translation y se basa en un concepto ya familiar para el lector: el uso de una interlingua (Johnson et al. 2016). La pregunta es, ¿cuándo alcanzarán un nivel de calidad suficiente para que puedan introducirse en los flujos de trabajo profesionales? De momento ya hay proyectos, como el recién finalizado Modern MT, que pretenden que esta realidad sea cada vez más cercana.
Conclusión
En cualquier caso, la traducción automática ha llegado al mundo de la traducción profesional y ha venido para quedarse. Con ella se abre un nuevo mundo de oportunidades y de retos a los que el traductor profesional deberá adaptarse. Dentro de muy poco, es posible que junto con los motores de TA aparezcan módulos de posedición automática o de estimación automática de la calidad de la TA con el objetivo de agilizar aún más los procesos y vencer las reticencias a utilizar una tecnología cada vez más presente en este sector. La traducción es, como muchas otras, una profesión supeditada a los avances tecnológicos. Del mismo modo que las herramientas de traducción asistida por ordenador acabaron convirtiéndose en herramientas fundamentales para la gran mayoría de los traductores profesionales, estoy convencida que dentro de unos años miraremos atrás y veremos que algo similar sucedió con la TA. Mientras tanto, formémonos, entendamos cómo funciona un motor, aprendamos a evaluarlos y preparémonos para las nuevas tareas de posedición que ya no son tan nuevas. Solo así convertiremos una tecnología que muchos temen en una herramienta más que facilitará nuestro trabajo.
Agradecimientos
Este artículo ha sido escrito gracias a la financiación del programa de investigación e innovación Horizonte 2020 de la Unión Europea dentro del marco de las becas Marie Skłodowska-Curie (acuerdo n.º 713567) y Science Foundation Ireland en el ADAPT Centre (Grant 13/RC/2106) en Dublin City University.
Bibliografía
Bahdanau, D.; Cho, K.; Bengio, Y. «Neural Machine Translation by Jointly Learning to Align and Translate». Computing Research Repository, abs/1409.0473 (2014) [16/02/2018].
Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. «Neural versus Phrase-Based Machine Translation Quality: a Case Study». Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP 2016), p. 257-267.
Burschardt, A., Macketanz, V.; Dehdari, J.; Higold, G.; Peter, J-T.; Williams, P. «A Linguistic Evaluation of Rule-Based, Phrase-Based, and Neural MT Engines». The Prague Bulletin of Mathematical Linguistics, 108 (2017), p. 159-170.
Calixto, Iacer; Stein, Daniel; Matusov, Evgeny; Lohar, Pintu; Castilho, Sheila; Way, Andy. «Using Images to Improve Machine-Translating E-Commerce Product Listings». Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers [Valencia] (2017), p. 637–643.
Castilho, S.; Moorkens, J.; Gaspari, F.; Calixto, I.; Tinsley, J.; Way, A. «Is Neural Machine Translation the New State-of-the-Art?». The Prague Bulletin of Mathematical Linguistics, 108 (2017a), p. 109-120.
Castilho, S., Moorkens, J.; Gaspari, F.; Sennrich, R.; Sosoni, V.; Georgakopoulou, Y.; Lohar, P.; Way, A.; Valerio, A; Miceli Barone, A. V.; Gialama, M. «A Comparative Quality Evaluation of PBSMT and NMT using Professional Translators». Proceedings of the MT Summit 2017 (2017b).
Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. «On the Properties of Neural Machine Translation: Encoder-Decoder Approaches». Computing Research Repository, abs/1409.1259 (2014).
Forcada, M. L. «Making sense of neural machine translation» Translation Spaces, 6:2 (2017) p. 291-309.
Forcada, M.; Ñeco, R. P. «Recursive hetero-associative memories for translation». Biological and Artificial Computation: From Neuroscience to Technology [Berlin], Mira J., Moreno-Díaz R., Cabestany J. (eds) (1997) p. 453-462.
Johnson, M.; Schuster, M.; Le, Q. V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G. «Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation». ArXiv (2016), 1611.04558.
Popović, M. «Comparing Language Related Issues for NMT and PBMT between German and English». The Prague Bulletin of Mathematical Linguistics, 108 (2017), p. 209-220.
Sennrich, R.; Haddow, B.; Birch, A. «Neural Machine Translation by Jointly Learning to Align and Translate». Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (2016) p. 1715-1725.
Toral, A.; Sánchez-Cartagena, V. M. «A Multifaceted Evaluation of Neural versus Statistical Machine Translation for 9 Language Directions». Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics [Valencia] (2017).
Wu, Yonghui; Schuster, Mike; Chen, Zhifeng; V. Le, Quoc; Norouzi, Mohammad; Macherey, Wolfgang; Krikun, Maxim; Cao, Yuan; Gao, Qin; Macherey, Klaus; Klingner, Jeff; Shah, Apurva; Johnson, Melvin; Liu, Xiaobing; Kaiser, Łukasz; Gouws, Stephan; Kato, Yoshikiyo; Kudo, Taku; Kazawa, Hideto; Stevens, Keith; Kurian, George; Patil, Nishant; Wang, Wei; Young, Cliff; Smith, Jason; Riesa, Jason; Rudnick, Alex; Vinyals, Oriol; Corrado, Greg; Hughes, Macduff; Dean, Jeffrey. «Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation». CoRR, abs/1609.08144 (2016).
1 Este formalismo es el que se empleaba en el proyecto del séptimo programa marco Molto que mencionábamos en la presentación.
2 Para el lector curioso recomiendo la lectura de un artículo publicado en diciembre de 2017 y titulado Making sense of neural machine translation escrito por Mikel Forcada y en el que trata de explicar a traductores y lingüistas cómo funciona un motor de traducción automática neuronal por dentro.

Carla Parra Escartín
Es investigadora Marie Skłodowska-Curie en Dublin City University (DCU), dentro del centro de investigación interuniversitario ADAPT. Es doctora en Lingüística Computacional por la Universidad de Bergen (Noruega) y licenciada en Filología Inglesa, Traducción e Interpretación (alemán-inglés-español) y Lingüística. Ha trabajado como traductora, revisora y directora de proyectos en plantilla y también como traductora autónoma.
