
Hoy en día, son pocos los traductores que no han oído hablar alguna vez de Xbench. A pesar de su creciente popularidad, muchos no se han decidido todavía a probarlo y otros tantos, que incluso ya lo tienen instalado en su equipo, no han llegado a descubrir las enormes posibilidades que les puede ofrecer esta aplicación gratuita de gestión terminológica y QA en su trabajo diario. Este artículo pretende servir como una introducción exhaustiva al programa para todos aquellos que no se hayan iniciado todavía en él y, para los que ya lo han hecho, incluye detalles y consejos de uso que les ayudarán a sacar un mayor partido a esta polivalente herramienta.
Xbench se ha hecho un importante hueco en la industria del software aplicado a los procesos de traducción dentro de la clasificación de las llamadas «herramientas independientes de terminología (Standalone terminology tools)» establecida por el experto en tecnología aplicada a la traducción Jost Zetzsche (véase el recuadro); se trata de aplicaciones que se ejecutan de manera externa a los programas TAO con referencia cargada y lista para ser consultada en un segundo plano. Hay que tener en cuenta que estas herramientas no impiden ni remplazan el uso de las funciones terminológicas integradas con las que cuentan la mayoría de los programas TAO (que posibilitan la búsqueda automática de términos y su aplicación interactiva en la traducción desde la misma interfaz en la que se trabaja), sino que sirven más bien como complemento de estas últimas, ya que permiten incluir más material de referencia que puede gestionarse desde múltiples fuentes de datos.
A diferencia de otras opciones de software dentro de esta misma categoría, como Lingo o Anylex, Xbench ha conseguido desmarcarse ofreciendo de una manera totalmente gratuita unas notables características técnicas en constante mejora y evolución. Esto ha sido posible gracias a que Xbench está creado por un equipo de experimentados profesionales de la traducción que han ido cubriendo con el programa sus propias necesidades de gestión terminológica y QA, y que, de forma más bien desinteresada, han decidido compartir los frutos de su trabajo con toda la comunidad de traductores. Detrás de este perfil, se encuentra ApSIC, una compañía española de traducción y localización ubicada en Barcelona, con cuyo director general hemos tenido el placer de compartir un rato de charla. En la entrevista que nos ha concedido y que acompaña a este artículo, Josep Condal da respuesta a diversas cuestiones sobre la historia y el desarrollo del programa, adelanta las novedades de la nueva versión en la que están trabajando actualmente y, por último, nos comenta el futuro que le augura a la aplicación en los próximos años.
¿Qué es Xbench?
Xbench es un programa gratuito de código cerrado que tiene dos elementos principales: gestor terminológico multifuente y herramienta de control de calidad. En el número anterior de La Linterna, Oliver Carreira nos habló concisamente de sus propiedades como herramienta de control de calidad, en comparación tanto con otros programas como con las funciones específicas para la evaluación de la calidad con las que cuentan actualmente la mayoría de los programas TAO del mercado. En este artículo vamos a centrarnos en sus funciones de gestión terminológica, que curiosamente parecen ser las menos populares a pesar de ser la sólida base sobre la que se asienta el programa, tal como nos comenta Josep Condal al principio de la entrevista, pero sin olvidarnos en ciertos momentos de sus valiosas características de QA. Aunque en mi caso suelo utilizar QA Distiller como herramienta de control de calidad porque la considero algo más completa que Xbench, he de reconocer que este ofrece un rendimiento similar y que, además, es compatible con un mayor número de formatos, por lo que, si buscamos una herramienta de QA versátil y gratuita, Xbench, sin duda, es la respuesta.
Referencia disponible desde cualquier programa
Xbench funciona en segundo plano desde cualquier aplicación en la que el usuario esté trabajando. La secuencia del teclado que lanza la aplicación por defecto es Ctrl+Alt+Ins (si la búsqueda se hace en el idioma de origen). Una vez cargado el material de referencia, hay que seleccionar el término o segmento deseado y pulsar esta combinación de teclas para que el programa se abra con los resultados de la consulta. Si deseamos copiar el resultado de la búsqueda para pegarlo en nuestra aplicación de trabajo, con tan solo pulsar Intro se copiará en el portapapeles y la aplicación se minimizará automáticamente (si queremos minimizarla manualmente podemos pulsar Esc o el método abreviado estándar de Windows Alt+Espacio+N).
- Una vez que se haya iniciado, Xbench seguirá en ejecución aunque se cierre su ventana.
- La combinación de teclas para buscar desde el idioma de destino es Ctrl+Alt+tecla de retroceso (borrar).
- En ciertos programas como WordFast Pro o en formatos cerrados como PDF con datos de texto reconocido, hay que copiar manualmente el término antes de pulsar el método abreviado de búsqueda.
- Si pulsamos Intro para copiar un resultado que no sea una coincidencia exacta del término o segmento que hemos buscado, el programa nos avisará con un mensaje de advertencia (a no ser que desactivemos este mensaje desde los ajustes del programa).
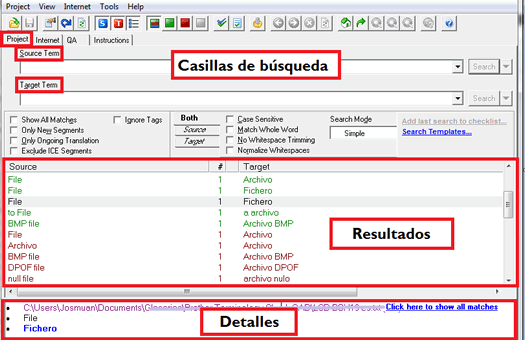
Referencia multifuente mediante una única búsqueda
El primer paso que tenemos que llevar a cabo para empezar a sacar provecho de Xbench es la creación de un proyecto, que es la unidad básica sobre la que se cargan las distintas bases de datos de referencia. De esta manera, cada vez que estemos trabajando en textos similares podremos abrir el proyecto de Xbench con los mismos archivos y ajustes que habíamos establecido anteriormente. Cada uno de los proyectos lo podemos crear en función de las características de nuestro trabajo personal: yo, por ejemplo, tengo proyectos creados para ciertas especializaciones (como financiero o fotografía) y otros los tengo según productos o clientes con los que suelo trabajar (para tener a mano no solo la referencia proporcionada para un proyecto de traducción o revisión en concreto, sino también todo el material de referencia de proyectos anteriores similares, como las memorias de traducción actualizadas).
Es probable que en ciertos proyectos en los que trabajemos el cliente nos facilite varias fuentes de referencia en diferentes formatos que debamos tener en cuenta a la hora de traducir el texto origen. En Xbench podemos cargar todo este corpus y, como veremos más adelante, ordenarlo según la prioridad. En el ejemplo siguiente, vamos a imaginarnos un proyecto de Xbench en el que tengamos que cargar una memoria exportada de Workbench, unos archivos bilingües de trabajo de WordFast Pro, un glosario financiero en Excel a partir de una página web, la base terminológica oficial de Microsoft y unos documentos ya traducidos anteriormente que necesitan ser alineados.
a) Archivos en formatos propios de programas TAO
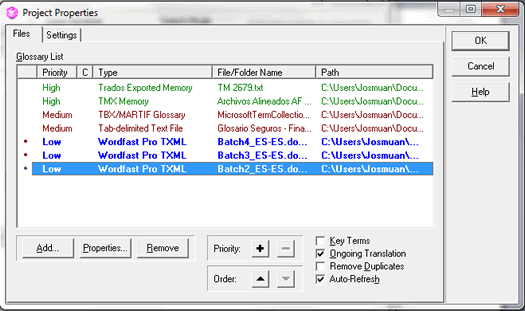
Una vez exportada la memoria desde Workbench, creamos el nuevo proyecto en Xbench e inmediatamente se nos abrirá la ventana de Project Properties. A continuación, pulsamos Add. Seleccionamos el tipo de archivo (en este caso: TradosExported Memory), hacemos clic en Next, añadimos la memoria exportada y seleccionamos sus propiedades.
Para añadir los archivos bilingües de trabajo que comentábamos, tenemos que pulsar Add/Properties; a continuación, seleccionamos el formato (Wordfast Pro TXML) y, por último, el archivo en cuestión. Estos archivos TXML, al igual que los XLIFF, TTX o ITD, se definen de forma predeterminada como Ongoing Translation. Si no desactivamos esta casilla, aparecerán señalados en negrita dentro de la lista del material de referencia del proyecto para diferenciarlos de los demás archivos cargados.
De esta manera tan sencilla podemos añadir glosarios, memorias y archivos bilingües de diferentes programas TAO, como Studio, SDLX, Wordfast o Déjà Vu en sus propios formatos, o cualquier otro archivo que hayamos exportado en los estándares TBX, TMX o XLIFF.
b) Glosarios en Excel
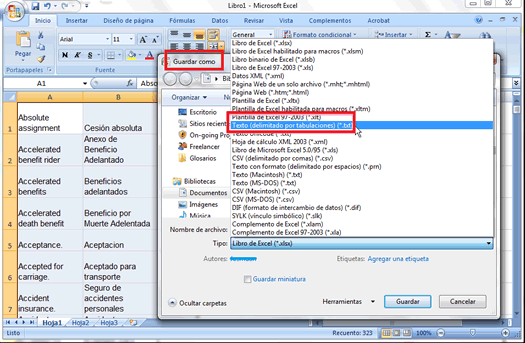
Aunque hay varias maneras de procesar glosarios en Excel, una de las más sencillas es copiar las columnas del idioma origen y destino en un archivo Excel nuevo al que guardaremos como Texto (delimitado por tabulaciones), desde Guardar como / Texto en otros formatos. Una vez que hemos creado el TXT, volvemos a Properties y lo añadimos como Tab-delimited Text File.
El glosario financiero que vamos a utilizar en este ejemplo, lo podemos obtener de esta web. En este caso, como sucede en muchas otras ocasiones, ciertos glosarios online, al copiar y pegar sus términos en un archivo Excel, se ordenan automáticamente según las celdas de la hoja de cálculo. A partir de aquí tan solo tenemos que crear el archivo TXT delimitado por tabulaciones tal y como hemos explicado en el párrafo anterior.
c) Glosario de Microsoft
Primero tenemos que descargarnos el glosario en TBX con el idioma de destino que nos interese desde esta web. En Properties/Add marcamos la opción TBX/MARTIF Glossary y seleccionamos el TBX que hemos descargado. Por último, configuramos las propiedades y los idiomas que queremos que sean el origen y el destino de las búsquedas potenciales.
d) Material de referencia que necesita ser alineado
Para alinear documentos traducidos a partir de sus respectivos originales de una manera más rápida que con las herramientas habituales de alineación de los programas TAO, os recomiendo LF Aligner, un programa gratuito creado por un traductor húngaro, que utiliza un algoritmo que automatiza la alineación de una manera bastante aproximada. Para conocerlo con más detalle, podéis leer la entrada que he escrito en mi blog sobre él. Con LF Aligner podemos crear una memoria en TMX que también se puede añadir en nuestro proyecto de Xbench desde Properties.
- Los archivos que se marquen como On-going Translation pueden analizarse con las opciones de control de calidad de la pestaña QA.
- Cuando estamos trabajando con un programa TAO en documentos que han sido pretraducidos es recomendable cargar en Xbench el archivo o archivos en los que estamos trabajando para poder consultar y priorizar la terminología de las pretraducciones o de nuestras propias traducciones según vamos avanzando en ellas. Para que los archivos en los que estamos trabajando se actualicen podemos pulsar la opción View/Refresh (o F5 en el teclado), o si queremos que la actualización se haga automáticamente con cierta frecuencia podemos activar la casilla Auto-Refresh y definir, desde los ajustes (Settings) del proyecto, cada cuántos minutos queremos que se realicen las actualizaciones.
- Una función interesante que se ha incluido en las últimas versiones del programa es la posibilidad de tener dos proyectos de Xbench cargados en la memoria al mismo tiempo. De esta manera, si, por ejemplo, estamos traduciendo el manual de una cámara de fotos de la marca A y buscamos un término fotográfico en el proyecto de Xbench con todo el material de referencia de A sin obtener ningún resultado adecuado, podemos tener abierto el material de referencia de la marca B, como proyecto alternativo, y buscar tal término automáticamente pulsando Alt+F6. Si lo pulsamos de nuevo, se vuelve a alternar la búsqueda entre los dos proyectos cargados.
Formatos admitidos
Xbench puede presumir de ser, probablemente, el programa que procesa el mayor número de formatos del sector, ya sea para cargarlos como un corpus o para analizarlos en las labores de QA.
Tab-delimited text files (*.txt)
XLIFF files (*.xlf, *.xlif, *.xliff)
TMX memories (*.tmx)
TBX/MARTIF glossaries (*.xml, *tbx, *.mtf)
Trados exported memories (*.txt)
Trados exported MultiTerm 5 glossaries (*.txt)
Trados MultiTerm XML glossaries (*.xml)
Trados TagEditor files (*.ttx)
Trados Word uncleaned files (*.doc, *.rtf)
Trados Studio files (*.sdlxliff, *.sdlproj)
SDLX ITD files (*.itd)
SDLX Memories (*.mdb)
STAR Transit 2.6/XV directory tree
PO files (*.po)
IBM TranslationManager exported dictionaries (*.sgm)
IBM TranslationManager installed and exported folders (*.fxp)
IBM TranslationManager exported memories (*.exp)
OpenTM2 exported dictionaries (*.sgm)
OpenTM2 installed and exported folders (*.fxp)
OpenTM2 exported memories (*.exp)
Wordfast memories (*.txt)
Wordfast glossaries (*.txt)
Wordfast Pro TXML files
DejaVu X/Idiom files (*.wsprj, *.dvprj)
DejaVu X/Idiom memories (*.wstm, *.dvmdb)
Logoport RTF files (*.rtf)
Microsoft software glossaries (*.csv)
Mac OS X glossaries (*.ad)
Remote Xbench Server glossaries
Orden de la prioridad y simbología utilizada
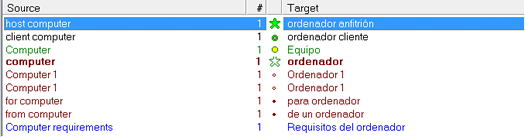
Una característica muy útil con la que cuenta Xbench es la posibilidad de ordenar con detalle cada una de las fuentes de referencia de un mismo proyecto según la prioridad que nos convenga o que nos haya indicado el cliente. Cuando introducimos nuevos archivos de referencia en un proyecto, al establecer sus ajustes tenemos que elegir la prioridad entre alta (verde), media (marrón) y baja (azul). Cuando estemos buscando un término o segmento en el proyecto, los resultados aparecerán en orden de prioridad y con el color respectivo a cada nivel. Los grados de prioridad se puede modificar fácilmente desde la pantalla de propiedades del proyecto con los botones + y –. Desde esta ventana también podemos organizar el orden de las fuentes de referencia dentro de un mismo nivel de prioridad mediante ▲ y ▼.
Si la referencia consultada coincide totalmente, aparecerá un círculo verde entre los dos idiomas del resultado. Si la coincidencia es total exceptuando el uso de las mayúsculas y minúsculas aparecerá un círculo amarillo.
Asimismo, es posible establecer uno de los archivos de la referencia como el más prioritario de todos definiéndolo en sus propiedades como Key terms. Los resultados de búsqueda pertenecientes a tal archivo aparecerán en primer lugar y acompañados por una estrella. De manera similar a los resultados de la referencia normal, la estrella es verde cuando el término es una coincidencia total; amarilla cuando lo es a excepción de las mayúsculas y minúsculas, y blanca si el término buscado aparece junto con otras palabras adicionales.
Los resultados provenientes de archivos bilingües de trabajo (TTX, TXML, ITD, XLIFF…) que hayamos marcado como Ongoing Translation aparecerán con un punto: estará vacío cuando se trate de un segmento bloqueado Xtranslated o 100 %, y estará relleno cuando sea un segmento con un porcentaje de entre el 0 % y el 99 %.
- El glosario que marquemos como Key terms se utilizará también en las tareas de QA para verificar la terminología en el archivo o archivos que hayamos marcado como Ongoing Translation.
- Los símbolos circulares que indican el nivel de coincidencia de los resultados de la búsqueda se combinan con los puntos pequeños que determinan qué tipo de segmento son los archivos establecidos como Ongoing Translation. De este modo, por ejemplo, Xbench muestra una coincidencia total de un segmento Xtranslated con el símbolo siguiente:

Tipos de búsqueda
Además de las búsquedas simples que Xbench realiza de manera predeterminada, por las cuales se obtienen resultados equivalentes al término o segmento deseado según el orden introducido, también existen otras opciones de búsqueda más precisas y restringidas.
Por una parte, tenemos la opción PowerSearch, que podemos activar cada vez que pulsemos la combinación Ctrl + P o la seleccionemos pulsando ▼ en el botón Search. Con esta función podemos realizar búsquedas que contengan una o varias cadenas de palabras que no aparezcan necesariamente en los resultados con el orden establecido en la casilla de búsqueda.
- Si añadimos entre las dos cadenas or, la búsqueda se realizará buscando una cadena o la otra.
- Añadiendo el signo – antes de una de las cadenas, se restringirá la búsqueda, de manera que aparezcan las demás cadenas pero no la precedida por este signo.
En la práctica, yo utilizo la combinación de teclas de PowerSearch casi de manera automática cada vez que hago una búsqueda normal de un segmento y no obtengo resultados; es una manera de buscar a lo fuzzy cuando no ha habido ninguna coincidencia total.
Xbench también admite búsquedas sumamente precisas gracias al uso de expresiones regulares y caracteres comodín de Word (MS Word Wildcards), un lenguaje de metacaracteres con un significado preestablecido que sirve para buscar y reemplazar patrones textuales que se repiten en un documento. Por ejemplo, (p|m)adre nos serviría para buscar frases en las que aparezca tanto padre como madre.
Para acceder a estas opciones hay que pulsar View/Search Options o el botón correspondiente. Como se puede observar en la ilustración, al activar este panel también se accede a varias opciones de restricción de búsqueda, como distinguir mayúsculas/minúsculas o excluir ciertos tipos de segmentos en los resultados. Si queréis obtener una visión general de los metacaracteres que podemos utilizar en Xbench, es recomendable consultar el capítulo 5 del Manual del usuario de Xbench, donde vienen explicadas y ejemplificadas las distintas expresiones admitidas por el programa. En la interfaz de Xbench, de hecho, se incluyen unas plantillas con búsquedas predefinidas que utilizan este lenguaje, a las que se puede acceder desde la opción Search templates.

- Una expresión sencilla y sumamente útil a la hora de realizar búsquedas más específicas en Xbench es la formada por los patrones < o >. Por ejemplo, si queremos buscar deal pero queremos evitar entradas en las que aparezca dealer o dealing, tenemos que introducir en la casilla de búsqueda deal>. De la misma manera, <view evitaría que en los resultados se incluyese preview u overview.
Modificación de entradas
Xbench permite acceder fácilmente a los archivos originales en los que hayamos encontrado errores, ya sea en la referencia consultada de un proyecto o en los resultados de un control de calidad efectuado en los archivos marcados como Ongoing Translation.
En el momento que Xbench nos muestre un resultado que queremos modificar, si pulsamos la combinación Ctrl + Alt + Intro Xbench abrirá automáticamente el archivo original en una aplicación externa para que podamos modificarlo.
Si el archivo tiene un formato bilingüe de trabajo, como por ejemplo TTX o ITD, Xbench ejecutará TagEditor o SDLX respectivamente y abrirá el archivo justo en la ubicación del segmento pertinente.
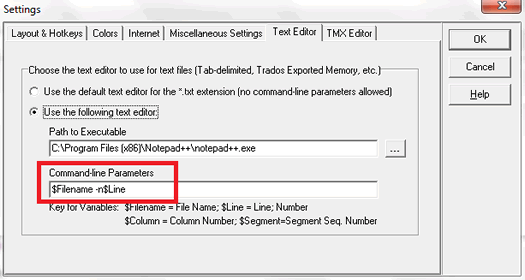
Para archivos TXT (como los que hayamos delimitado por tabulaciones) y las memorias TMX, es recomendable enlazar un programa de edición de código fuente que tengamos instalado en nuestro equipo. Esto lo podemos hacer desde Tools/Settings/Text Editor – TMX Editor. Yo utilizo Notepad++, una aplicación gratuita que ofrece unas funciones avanzadas de edición que vienen muy bien a la hora de trabajar con este tipo de archivos. Para configurarlo correctamente tenemos que añadir la ruta en la que se encuentra su archivo ejecutable y, si incluimos los parámetros $Filename -n$Line, Xbench podrá abrir el archivo en la ubicación exacta en la que hay que realizar la modificación.
Exportación en TXT o TMX
La versatilidad de Xbench también se puede apreciar en sus valiosas funciones de conversión entre la gran mayoría de los formatos de la industria. Desde el menú Tools/Export items es posible exportar todos los archivos de referencia de un proyecto, solo uno de ellos o los resultados de la búsqueda actual. Además, podemos filtrar los términos o segmentos según su condición, eliminar las repeticiones y excluir los segmentos ICE (es decir, los que son equivalentes totales incluso con respecto a su contexto; también denominados en otras aplicaciones como 101 %).
El archivo resultante se puede exportar en el estándar TMX, que es admitido prácticamente por todos los programas de traducción asistida del mercado, o bien en TXT delimitado por tabulaciones, que es un formato idóneo para la elaboración de glosarios.
Búsquedas online
Aunque para este tipo de menesteres recomiendo encarecidamente la aplicación gratuita IntelliWebSearch, también es digna de nombrar la función de búsquedas automáticas en Internet de Xbench. Cuando no encontremos un término en nuestro proyecto cargado en Xbench, si pulsamos Alt+[Núm], se nos abrirá la pestaña Internet y se buscará el término en el sitio web correspondiente al número pulsado.
De forma predeterminada, Xbench incluye búsquedas en Google y Google Define (aunque parece que este servicio de Google ya no está disponible), que corresponden a Alt+1 y Alt+2 respectivamente, pero fácilmente podemos añadir otros sitios web en los que habitualmente llevemos a cabo búsquedas.
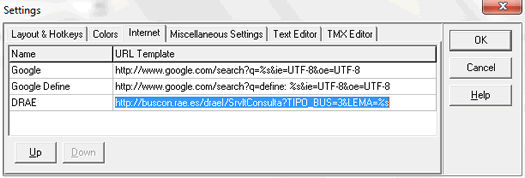
Para añadir un nuevo sitio web, primero accedemos a él desde un navegador cualquiera y hacemos una búsqueda de prueba. Copiamos la URL de la página que ha mostrado los resultados, y desde Xbench nos vamos a Tools/Settings y a la pestaña Internet. En la línea disponible siguiente introducimos un nombre (por ejemplo, DRAE) y a su lado pegamos la URL. Entonces, tenemos que sustituir en la URL la palabra que habíamos buscado como prueba, por %s. De esta forma, Xbench podrá buscar en esta página los términos que tengamos en la casilla de búsqueda tras haber pulsado Alt y el número correspondiente a la web configurada.
Instrucciones de proyecto
Una característica simple pero sumamente útil es la pestaña Instructions, donde tenemos un espacio de edición de texto en el que podemos añadir cualquier tipo de anotación personal que sea pertinente para el proyecto que tengamos abierto. Por ejemplo, podríamos anotar las respuestas que el cliente nos ha dado a las preguntas que le habíamos hecho en traducciones previas; la URL desde la que pudimos encontrar la traducción de un término complicado para poder consultarlo en el futuro; el truco de la macro que descubrimos para convertir los puntos en comas y viceversa, etc. Si tenéis en cuenta que este espacio existe, seguro que encontráis datos valiosos e interesantes en vuestro trabajo diario para registrarlos en esta sección.
Checklists
Al principio del artículo comparaba la aplicación con QA Distiller, otro programa de control de calidad de pago que ofrece unas funciones de QA algo más completas que Xbench. Aunque no estemos tratando exhaustivamente sus características en este ámbito, hay una opción de QA que merece la pena destacar por ser mucho más interesante que la de otros programas gracias a su fácil personalización y a que hace uso de la potente tecnología de búsqueda de Xbench: las checklists.
Estas listas son una serie de búsquedas personales que podemos realizar conjuntamente en nuestros archivos traducidos para localizar las incorrecciones que establezcamos. Estas pueden ser, por ejemplo, errores típicos del idioma al que estamos traduciendo, ciertos términos que el cliente quiere que no se utilicen, nombres propios que nos queremos asegurar que siempre salgan escritos correctamente, etc. Cualquier búsqueda que se pueda hacer en Xbench es susceptible de ser añadida en una de estas listas.
Desde Tools/Manage Checklists, creamos una lista. Las listas pueden ser Project Checklists, que son listas integradas en el proyecto de Xbench que pueden servir para buscar errores típicos, propios del proyecto que tenemos abierto, como los resultantes del feedback del cliente en anteriores proyectos, una lista de términos prohibidos, etc. O bien Personal Checklists, que se crean en un archivo independiente y son listas adecuadas como una relación de errores generales, como faltas ortográficas que normalmente no detecta la función de ortografía de otros programas o que el traductor se da cuenta que suele cometer y quiere asegurarse de no haber realizado.
Para añadir elementos en las listas creadas, tenemos que hacer la búsqueda de una manera normal en Xbench y, una vez que se hayan mostrado los resultados, hay que pulsar la opción Tools/Add last search to checklist. En la ventana que aparece, podemos añadir un título y una descripción, categorizar el error y elegir las opciones de búsqueda que se aplicarán para tal elemento de la lista.
Cuando hayamos incluido todas las búsquedas deseadas en las listas, las podremos ejecutar desde la pestaña QA: hay un botón específico para las listas del proyecto, otro para las personales y, además, existe la posibilidad de ejecutarlas en lote a la vez que las demás opciones de QA.
Conclusión
Como he intentado mostrar, Xbench es una herramienta multifunción que puede optimizar con creces la calidad final de una traducción. Además, su conocimiento en la actualidad no solo proviene de la decisión propia del traductor de utilizarlo, sino que también cada vez son más las empresas proveedoras de servicios lingüísticos que exigen a sus colaboradores externos el uso de Xbench como parte de los procesos que conlleva una traducción.
Bien es cierto que, al igual que las demás aplicaciones de terminología y control de calidad, su uso puede que no sea tan necesario en función del tipo de traducción a la que cada uno se dedique, como, por ejemplo, la traducción literaria o creativa; pero para las traducciones funcionales, cuyos pilares básicos son el uso coherente de la terminología y la consistencia textual, estos programas ya se han convertido en una realidad indispensable en el trabajo del traductor y el revisor.
Para finalizar, recomiendo consultar la completa guía del usuario que ApSIC también ha elaborado para la aplicación; otro lujo adicional con el que cuenta este programa freeware. De hecho, este manual ha sido ya traducido a otros cuatro idiomas por usuarios de manera desinteresada. Al parecer, todavía nadie se ha decidido a hacer la traducción al castellano, por lo que dedicarse a ello podría ser una excelente manera de agradecer a ApSIC en nombre de todos los lectores de La Linterna el arduo y fructífero trabajo que hay detrás de esta extraordinaria herramienta. ![]()
Palabras de gurú para La Linterna: Jost Zetzsche sobre Xbench
Jost Zetzsche es un traductor, consultor, sinólogo y escritor alemán establecido en Estados Unidos. Gracias a sus amplios conocimientos en localización y tecnología aplicada a la traducción, se ha ganado la fama de «gran maestro» de la industria. Comparte las últimas novedades tecnológicas del sector en un interesante boletín electrónico mensual al que es posible inscribirse gratuitamente en su versión básica. Es autor del aclamado libro A Translator’s Tool Box—A Computer Primer for Translators y comparte la autoría de Found in Translation: How Language Shapes Our Lives and Transforms the World, que se va a publicar en octubre de este año. Es posible consultar más información sobre Jost en su página web o través de Twitter en su perfil @jeromobot.
No hay ninguna otra historia sobre el desarrollo de un programa de software que me haya impresionado tanto como la de ApSIC Xbench: una herramienta que la gran mayoría de los proveedores de servicios lingüísticos dan por hecho que estará instalada en el ordenador del traductor profesional con el que quieren colaborar (sin ir más lejos, en este último mes, he debido de trabajar en al menos tres proyectos de diferentes clientes en cuyas instrucciones se exigía el uso de Xbench; casi al mismo nivel que otros programas como MS Word o un navegador web).
Xbench es una herramienta que permite leer archivos en un gran número de formatos —entre los que se incluyen glosarios, bases de datos terminológicas y memorias de traducción— y realizar búsquedas en todos ellos a la velocidad de la radiación de Cherenkov (para aquellos que no se hayan en iniciado en la física molecular, me refiero a una velocidad increíblemente alta). Además, permite llevar a cabo distintos controles de calidad formales (no idiomáticos) en estos archivos.
Para la última versión del programa, el equipo de desarrollo de Xbench preguntó a su comunidad de usuarios cuáles eran los formatos que todavía faltaban en su ya extenso repertorio y, que yo sepa, todos los deseos han sido virtualmente concedidos. «Algo normal», como se podría afirmar si tenemos en cuenta los abusivos precios que los traductores estamos pagando últimamente por programas de software. Bueno, no en este caso: aunque parezca mentira, ¡Xbench es gratis! ![]()

José Carlos Gil
Es un traductor burgalés afincado en Ámsterdam especializado en textos jurídicos, en documentación técnica y en la traducción creativa comercial. Tras realizar sus estudios en la Facultad de Traducción e Interpretación de Soria (UVA) e iniciar un programa de doctorado en la Universidad de Granada, comenzó su andadura profesional en los Países Bajos como traductor en plantilla de una multinacional japonesa en donde adquirió la experiencia suficiente para lanzarse al mercado de la traducción con el nombre comercial de Bluebird Translations. Actualmente, comparte oficina con otros profesionales independientes de Ámsterdam en el corazón del Jordaan. Es uno de los tres coautores del blog Con el calco en los talones.
